Graph4Rec的CPU分布式训练运行失败 #483
Comments
|
请按照README 的步骤,一步一步运行看看。 |
|
如果有k8s 集群,就不用手动在各自机器上launch服务了。 支持的模型都在user_congfigs/目录里面体现了。 metapath2vec, lightgcn都是支持的。 |
|
我是按readme执行的,但是执行Distributed CPU training and inference in a single machine小节的fleetrun报错退出了。只看到截图的报错信息,不知道是什么原因 |
|
paddle的版本是按照要求的吗? |
paddlepaddle-gpu是2.3.1(readme是2.3.0)、pgl是2.2.4(同readme)。paddle要降级吗? |
|
最好按照要求的来。 |
我将paddlepaddle-gpu版本降级到了2.3.0了,但是还是同样的问题。 |
|
补充说明一下,我看了一下trainer的日志,其实是有在跑的。启动了4个worker,worker0的日志正常打印Loss日志,但是最后没有保存模型,看到”saving model to ../../ckpt_custom/metapath2vec.0712“,但是目录下没有产出ckpt.pdparams,而是产出了一个000目录,下面是一堆part-**文件,看了一下文件内容,是一串数字(空格分隔,维度是72)。这是什么数据呢,为什么没有产出模型和单个embedding文件呢? |
|
这是分布式训练,那个000目录就是模型文件了。 embedding需要另外infer,readme有写。 |
啊啊,是的,试出来了😂谢谢了!我再试下多机CPU分布式。 |
请问下多机多CPU执行,ip_list.txt内容和参数中的--workers和--servers是什么关系呢?我试了一下没有改ip_list.txt(就是原始的127.0.0.x,4条记录),然后分别在两台机器上启动服务部署和训练程序。发现速度并没有预期的比单机快2倍,感觉更慢了?我看fleet_logs下只有一个worker.0和server.0,是没有成功多机多cpu吗? |
|
@Liwb5 抱歉打扰了,请问下上面这个多机多CPU的应该如何排查呢?谢谢 |
|
没有直接关系。 ip_list.txt 只是为了来启动图引擎。 单机情况下ip_list可以写127.0.0.1, 多机情况下就是要写每台机的真实ip地址。然后在每台机上启动图引擎。 成功启动图引擎之后,再在每台机上启动训练任务。 |
不同机器上的ip_list要写各自"ip地址:port",是吗?--servers和--workers的ip列表值表示什么含义,和ip_list的内容是不重叠的吗? |
@Liwb5 还在吗?fleetrun传递的servers和workers,如果和ip_list.txt的地址不相干的话,是用来做什么的?是随便设置两台机器ip+port就好(我就是随便设置的,但是如之前所述,好像没有成功进行多机多卡的训练)?不知道有没有关于这个分布式实现的原理性介绍。谢谢~ |
|
@Liwb5 HI,能否介绍一下fleetrun的实现原理?ip_list.txt是各个机器上启动图引擎,fleetrun的servers和workers是作什么用的呢?thanks |
|
这块得看一下paddlepaddle的官方文档: 比如这个。 |
|
@Liwb5 抱歉又来打扰了,我手动在两个容器间实现了多机多CPU训练。但是在训练更大的图时(约100亿条边,2000万个节点,Lightgcn;边文件大小约150GB)时,容器失败了。我看了一下
|
您好,我在单机上尝试Graph4Rec说到的单机训练,步骤如下:
1)先修改./toy_data/ip_list.txt文件,填写了ip地址,然后分别启动
2)然后执行单机分布训练
但是很快就报错(all parameter server are killed)退出了。(如果只写1个IP地址,即单机非分布式,是可以正常运行),看了server的报错日志
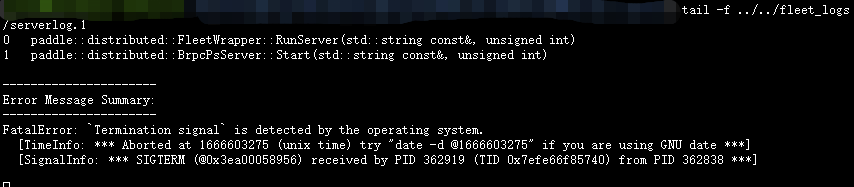
不知道这个是因为什么原因呢?
另外,如果多机分布式,是要将所有服务地址都先写好在ip_list.txt,然后在各自机器上执行launch启动服务,然后在任意一台执行fleetrun吗?是否已经直接支持了metapath2vec、lightgcn等模型的多机分布式训练?谢谢~
The text was updated successfully, but these errors were encountered: