
We recently heard from some in the Slack community that our published privacy principles weren’t clear enough and could create misunderstandings about how we use customer data in Slack. We value the feedback, and as we looked at the language on our website, we realized that they were right. We could have done a better job of explaining our approach, especially regarding the differences in how data is used for traditional machine-learning (ML) models and in generative AI.
Today, we updated those principles to more clearly explain how Slack protects customer data while providing both ML and generative AI experiences in Slack. Here’s what you need to know:
- Slack uses industry-standard, privacy-protective machine-learning techniques for things like channel and emoji recommendations and search results. We do not build or train these models in such a way that they could learn, memorize, or be able to reproduce any customer data of any kind. While customers can opt-out, these models make the product experience better for users without the risk of their data ever being shared. Slack’s traditional ML models use de-identified, aggregate data and do not access message content in DMs, private channels, or public channels.
- Slack’s add-on generative AI product, Slack AI, leverages third-party LLMs. No customer data is used to train LLM models. And we do not develop LLMs or other generative models using customer data.
Trust is our number one value, and that starts with transparency. Our customers deserve a crystal clear explanation of how we use—and, more importantly, how we don’t use—customer data to provide the best possible Slack experience.
This post will go a level deeper to provide even more clarity. We hope it helps, and as always, we value your feedback.
Protecting your data: Slack’s use of traditional machine learning models
Slack’s mission is to make people’s working lives simpler, more pleasant and more productive. There’s a lot of information in Slack, and to do your best work, you need to be able to navigate that content effectively and find what you need fast. Since 2017, we’ve used industry-standard, privacy-protective machine-learning techniques to help surface the right information to the right user at the right time—such as autocompleting a channel name as you begin typing in search, or recommending new channels to join in your workspace.
Our Privacy Principles guide how we use machine learning systems in Slack. We publish them externally to provide transparency and accountability. These principles align with Slack’s longstanding commitment to customer and user privacy. They ensure that:
- Data does not leak across workspaces. We do not build or train ML models in a way that allows them to learn, memorize, or reproduce customer data.
- ML models never directly access the content of messages or files. Rather, they rely on carefully derived numerical features. For example:
- A timestamp of the last message sent in a channel can help us recommend archiving a channel to simplify users’ channel sidebars.
- The number of interactions between two individuals is incorporated into the user recommendation list so that when a user goes to start a new conversation, they get a relevant list of co-workers.
- The number of words overlapping between a channel name and other channels a user is a member of can inform its relevance to that user.
- Technical controls prevent unauthorized access. When developing AI/ML models or otherwise analyzing customer data, Slack does not access the underlying content. We have various technical measures preventing this from occurring. Please read our Security White Paper for more information on these controls that protect the confidentiality and security of customer data.
- Customers have a choice in these practices. If you want to exclude your customer data from helping train Slack’s ML models, you can opt out, as documented here. Because we have strong protections in place to train these ML models safely so that we can provide the best possible product experience, workspaces are not opted out by default.
Below are some specific examples of how non-generative ML models are used in Slack to make it easy to find what you need:
Search ranking
Creating a prioritized and personalized list of results when a user searches for people, messages or files.
How it works:
Our search machine-learning models help users find what they’re seeking by identifying the right results for a particular query. We do this based on historical search results and previous engagements without learning from the underlying text of the search query, result, or proxy. Simply put, our models aren’t trained using the actual search query but learn from the context around the search, such as the number of words in a query.
Recommendations
Recommending relevant users, channels, emoji, and other content at various places in the product, like suggesting channels for you to join.

How it works:
We often recommend users join new public channels in their workspace so they can get the most value out of Slack. These suggestions are based on channel membership, activity and topic overlaps. We do this in a privacy-protective way by using open-source ML models, which haven’t been developed using Slack data at all, to evaluate topic similarity and output numerical scores. Our model makes recommendations based only on these numerical scores and non-customer data.
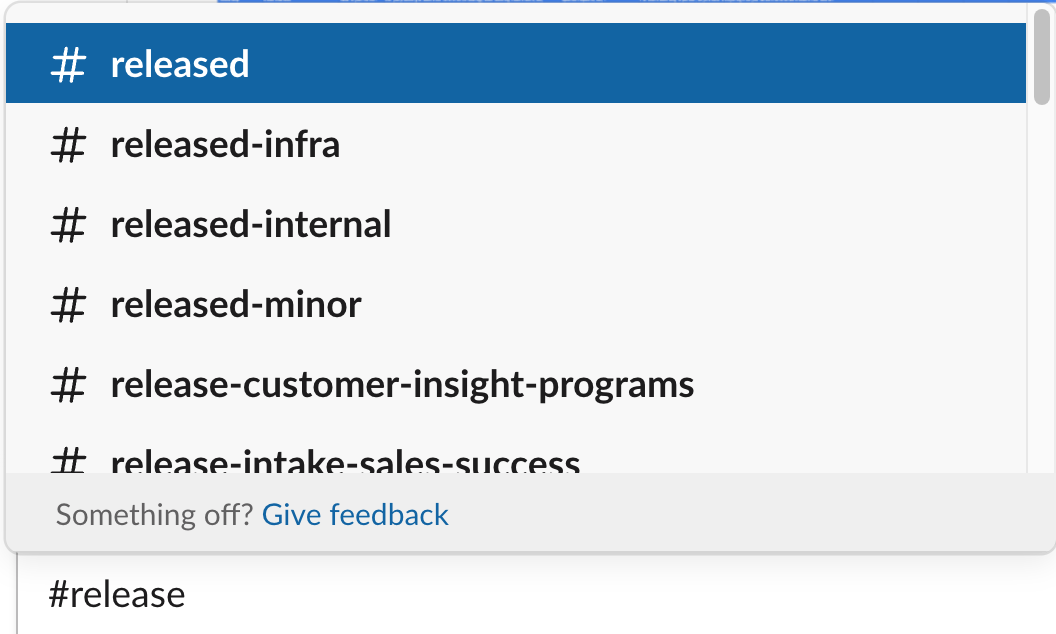
Autocomplete
Helping you add users, channels and file names to messages using the Slack search client.
How it works:
When users want to reference a channel or user in a message, they’ll start by typing # and beginning to type out the name of a channel. Our models will suggest the most relevant channels they may be searching for based on a number of inputs, including channels that the user is a member of and their recent and frequent channel interactions.
In summary, Slack’s traditional ML models use de-identified, aggregate data and do not access original message content in DMs, private channels, or public channels to make these suggestions. Instead, they collect aggregated data to improve search, make better recommendations, and offer suggestions.
Customer opt-out and user experience
Customers can email Slack to opt out of training non-generative ML models. Once that happens, all data associated with your workspace will be used to improve the experience in your own workspace. You will still enjoy all the benefits of our globally trained ML models without contributing to the underlying models. No product features will be turned off, although certain places in the product where users could have previously given feedback will be removed. The global models will likely perform slightly worse on your team, since any distinct patterns in your usage will no longer be optimized for.
In other words, any single customer opting out should feel minimal impact, but the greater number of customers who opt out, the worse these types of models tend to perform overall.
Enter generative AI
Generative AI introduces a new class of models that are used to improve the user experience, specifically large language models (LLMs). LLMs are used in Slack’s separately purchased add-on product, Slack AI. We have built Slack AI with security and trust top of mind, specifically:
- Customer data never leaves Slack.
- We do not train LLMs on customer data.
- Slack AI only operates on the data that the user can already see.
- Slack AI upholds all of Slack’s enterprise-grade security and compliance requirements.
Slack does not train LLMs or other generative models on customer data, or share customer data with any LLM providers.
You can read more about how we’ve built Slack AI to be secure and private here.
 Awesome!
Awesome!
Thanks so much for your feedback!
Got it!
Thanks for your feedback.
Oops! We're having trouble. Please try again later!