
最近,我们从 Slack 社区中听到的一些反馈,认为我们发布的隐私原则不够清晰明确,可能会让人对我们如何在 Slack 中使用客户数据产生误解。我们非常重视这些反馈,在查看我们网站上使用的语言之后,我们意识到这些反馈是对的。我们本可以更好地解释我们使用数据的方式,尤其是传统机器学习 (ML) 模型与生成式 AI 在数据使用方式方面的差异。
今天,我们更新了这些原则,以更清楚地说明 Slack 在提供 ML 和生成式 AI 体验的同时,是如何保护客户数据的。以下是你需要了解的信息:
- Slack 在频道和表情推荐以及搜索结果等功能中,使用了符合行业标准且保护隐私的机器学习技术。我们在构建或训练这些模型时,不会让它们学习、记忆或有能力重现任何类型的客户数据。虽然客户可以选择退出,但这些模型可以为用户提供更好的产品体验,而且没有泄露客户数据的风险。Slack 的传统 ML 模型使用去标识化的聚合数据,不会访问私信、私人频道或公共频道中的消息内容。
- Slack 的附加型生成式 AI 产品“Slack AI”使用第三方 LLM。在训练这些 LLM 模型时,我们没有使用客户数据。我们也不会使用客户数据开发 LLM 或其他生成式模型。
信任是我们的首要价值观,而信任始于透明。我们的客户理应得到清晰明了的解释,了解我们如何使用——以及更重要的是,我们如何不使用——客户数据来提供最佳的 Slack 体验。
这篇博文将进一步提供更加清晰的信息。我们希望这能有所助益,并且一如既往,我们重视你的反馈。
保护你的数据:Slack 对传统机器学习模型的使用
Slack 的使命是让人们在工作时更轻松、更愉快、更高效。Slack 中有大量信息,要想出色地完成工作,你必须能够有效地浏览这些内容,并快速找到所需信息。自 2017 年以来,我们一直在使用符合行业标准且保护隐私的机器学习技术,帮助在正确的时间向正确的用户呈现正确的信息,例如,在搜索时根据你输入的内容自动补全频道名称,或者在你的工作区推荐新频道以供加入。
我们的隐私原则是我们在 Slack 中使用机器学习系统的指南。我们对外发布这些原则,旨在帮助实现透明和问责。这些原则符合 Slack 对客户和用户隐私的长期承诺。它们确保:
- 数据不会在不同的工作区之间泄露。我们在构建或训练 ML 模型时,不会让它们学习、记忆或重现客户数据。
- ML 模型绝不会直接访问消息或文件内容,而是依赖于精心设计的数据特征。例如:
- 频道中最后一条消息的时间戳可以帮助我们向用户建议对频道进行归档,以简化用户的频道侧栏。
- 两个人之间的互动次数会纳入用户推荐列表中,这样用户在开始新对话时,就可以获得一个包含了相关同事的列表。
- 一个频道名称与用户所在其他频道的名称之间存在的词语重叠情况,可以表明该频道与这名用户之间的相关程度。
- 我们利用技术控制措施阻止未经授权的访问。在开发 AI/ML 模型或以其他方式分析客户数据时,Slack 无法访问底层内容。我们借助多种技术手段防止发生这种访问行为。请参阅我们的安全白皮书,进一步了解帮助保护客户数据机密和安全的相关控制措施。
- 我们允许客户选择是否参与此类训练。如果你不希望将你的客户数据用于帮助训练 Slack 的 ML 模型,可以选择退出,具体信息请参阅此处。由于我们已经采取了严格的保护措施,可以安全地训练这些 ML 模型,从而为客户提供最佳产品体验,因此默认情况下工作区没有退出。
以下是一些具体示例,展示了 Slack 如何使用非生成式 ML 模型来帮助你轻松找到所需内容:
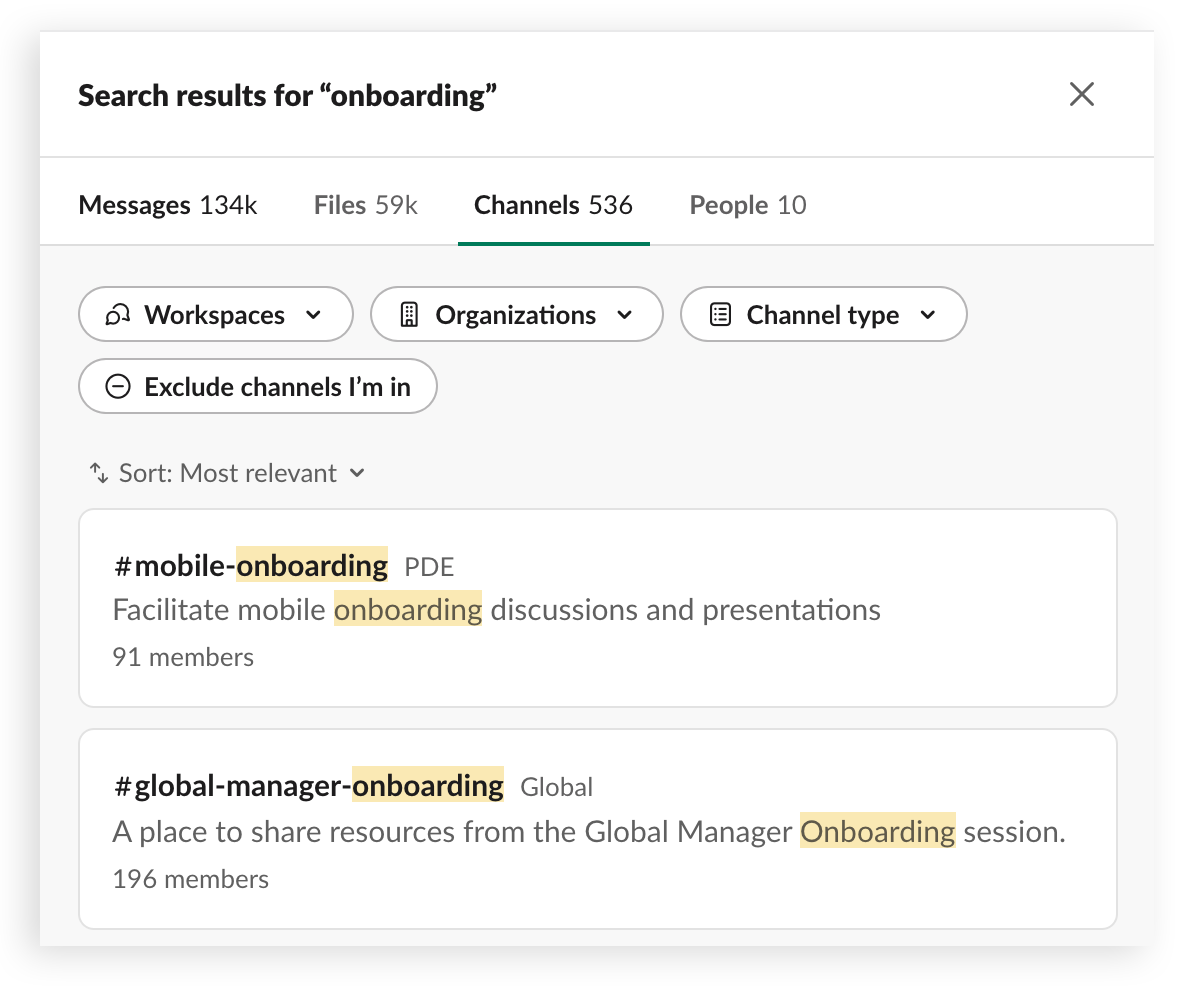
搜索结果排列
当用户搜索人员、消息或文件时,创建一个有序的、个性化的结果列表。
运作方式:
我们的搜索机器学习模型通过识别特定查询的正确结果,帮助用户找到所需内容。我们是基于历史搜索结果和以往的互动情况来做到这一点的,而不是从搜索查询��结果或代理的底层文字中学习。简单地说,我们的模型不是使用实际搜索查询来训练的,而是通过搜索的上下文进行学习,比如查询中的字数。
推荐
在产品的各个位置建议相关的用户、频道。表情和其他内容,例如建议你加入的频道。

运作方式:
为让用户充分利用 Slack,我们经常建议用户加入其工作区中的新公共频道。这些建议基于频道成员、活动和主题的重叠情况得出。为保护隐私,我们使用开源的 ML 模型来评估主题的相似性并输出数值分数。这种模型在开发时完全没有使用 Slack 数据,并且它只根据这些数值分数而非客户数据给出建议。
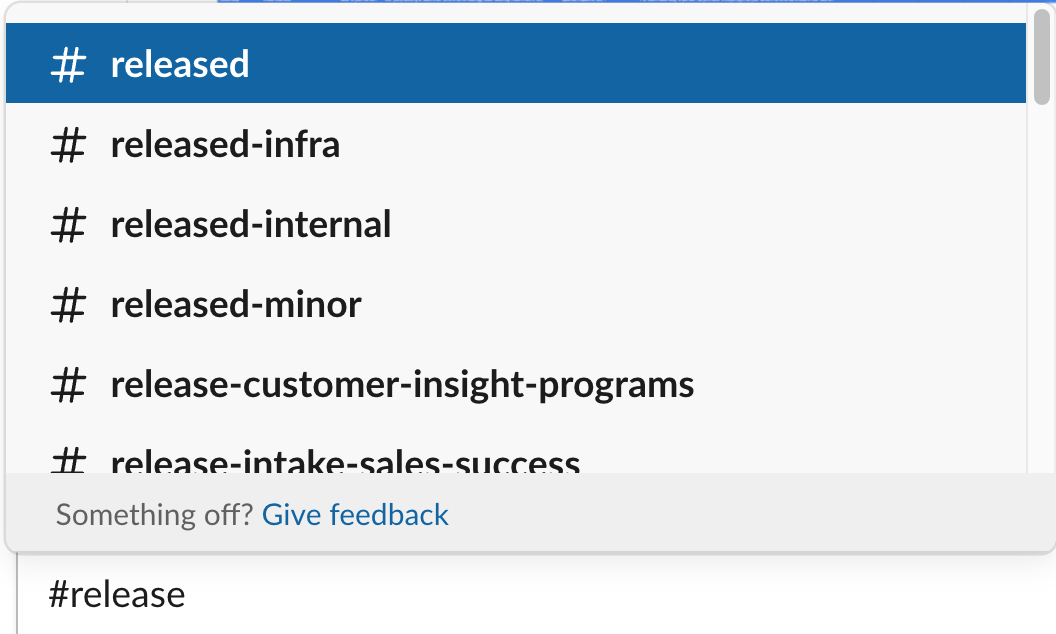
自动完成
帮助你使用 Slack 搜索客户端在消息中添加用户、频道和文件名称。
运作方式:
当用户想要在消息中引用频道或用户时,他们会首先键入 # 并开始输入频道的名称。我们的模型会基于一些输入信息(包括用户所在的频道和他们最近经常进行的频道互动)来建议他们可能正在搜索的最相关频道。
总的来说,Slack 的传统 ML 模型使用去标识化的聚合数据做出这些建议,而不会访问私信、私人频道或公共频道中的原始消息。它们会收集聚合的数据来改进搜索、提供更好的推荐和建议。
客户可以选择退出以及用户体验
客户可以给 Slack 发送电子邮件,选择不参加非生成式 ML 模型的训练。退出之后,与你的工作区相关的所有数据将用于提升你自己的工作区体验。你仍然可以享受我们全局训练的 ML 模型带来的好处,同时无需向底层模型贡献信息。所有产品功能都不会关闭,只不过用户之前可以给出反馈的某些位置将从产品中被移除。全局模型在你团队中的表现可能略差,因为模型不再针对你们的独特使用模式进行优化。
换句话说,一个客户选择退出,对整体模型的影响将很小,但如果越来越多的客户选择退出,这些模型的整体性能就会下降。
拥抱生成式 AI
生成式 AI 引入了一类用于提高用户体验的全新模型,特别是大型语言模型 (LLM)。Slack 的附加型产品“Slack AI”(须单独购买)使用了 LLM。我们在构建 Slack AI 时始终将安全和信任放在首位,具体体现在以下方面:
- 客户数据会始终保留在 Slack 中。
- 我们不会使用客户数据训练 LLM。
- Slack AI 仅针对用户已经可以看到的数据执行操作。
- Slack AI 符合 Slack 的所有企业级安全和合规要求。
Slack 不会使用客户数据来训练 LLM 或其他生成式模型,也不会与任何 LLM 提供商共享客户数据。
你可以在这里了解有关我们如何构建安全且私密的 Slack AI 的更多信息。
 太棒了!
太棒了!
非常感谢你提供反馈!
收到!
感谢你提供反馈。
糟糕!我们遇到问题了。请稍后重试!